Éléments de définition
Contents
Éléments de définition¶
À l’intersection des statistiques et de l’informatique, le machine learning se préoccupe de la modélisation des données. Les grands principes de ce domaine ont émergé des statistiques fréquentistes et bayésiennes, de l’intelligence artificielle ou encore du traitement du signal. Le machine learning est la science de l’apprentissage automatique d’une fonction prédictive à partir d’un jeu d’observations de données étiquetées ou non.
Ce chapitre se veut une introduction aux concepts et aux premières définitions qui fondent le machine learning, et en propose plusieurs approches, décrites et illustrées.
Donnée, jeu de données et caractéristiques¶
Une donnée est une quantité ou une observation mesurable.
Cela peut être la taille d’un individu, une image, du texte… À peu près n’importe quoi !
On peut récolter plusieurs données et les regrouper dans un jeu de données afin d’en étudier le fonctionnement d’un phénomène que l’on souhaiterai caractériser.
Par exemple, on pourrait mesurer la taille des adultes en France et regrouper ces mesures dans un jeu de données (dataset en anglais).
On dit alors que les données sont des exemples du dataset (ou sample en anglais).
Traditionnellement, on visualise un dataset à l’aide d’un tableau où les lignes sont les différents exemples et les colonnes sont les différentes mesures récupérées sur chaque exemple.
Individu ID |
Taille |
Couleur des cheveux |
Couleur des yeux |
|---|---|---|---|
1 |
1.75 |
Brun |
Marron |
2 |
1.92 |
Blond |
Bleu |
… |
Comme vous le voyez, il est possible de récolter plusieurs données pour un même individu.
Lorsqu’un exemple a plusieurs données attribuées, on parle alors de ses données comme de ses caractéristiques (features en anglais).
On dit que les exemples sont de dimension 3 dans notre cas, car ils ont 3 caractéristiques.
Dans le cas d’une image de 64x64 pixels, cette image peut être considéré comme un exemple avec 4096 caractéristiques !
Le jeu de données : la source de connaissances¶
En machine learning, tout part d’un jeu de données. Les données sont la clef de la connaissance, elles sont une image du fonctionnement du monde au moment où elles ont été récoltées. Voici quelques petits exemples pour illustrer l’utilité des données :
Mesurer la trajectoire d’un lancer de balle dans l’espace permet de mieux comprendre le fonctionnement de la gravité.
Lire l’ensemble des livres du XVIIe siècle permet de mieux comprendre comment s’exprimaient les populations de cette époque.
Comparer les achats de tous les clients d’un site marchand permet de mieux sélectionner les items à recommander aux futurs clients.
A travers les données, on peut déceler des comportements statistiques intéressants et en tirer de l’information. L’objectif du machine learning est d’extraire les connaissances contenues dans un jeu de données et de les synthétiser au sein d’un modèle.
Cependant, attention à ne pas tirer de conclusions hatives à partir d’un jeu de données. Les données ne sont pas neutres par essence. La façon dont elles ont été récoltées, le contexte, et des données manquantes externes peuvent totalement altérer l’information que vous avez extrait d’un jeu de données. Ainsi, des biais statistiques peuvent être insérés et pointer vers des conclusions dramatiquement fausses. Par exemple, on pourrait se dire que le chocolat rend plus intelligent car la plupart des personnes ayant reçu un prix nobel en consomment. Cependant, c’est oublié le facteur important ici : les pays les plus riches sont à la fois ceux qui investissent le plus dans la recherche et aussi ceux qui ont le plus accès au chocolat.
Le modèle : la synthèse des connaissances¶
Une fois les données récoltées, on souhaite généralement traduire les informations qui nous intéressent en un modèle.
Le modèle synthétise les connaissances contenues dans le jeu de données.
Il exprime mathématiquement les relations du dataset, sous forme de fonction.
Pour revenir sur les exemples précédents, un modèle :
Caractérise l’évolution de la position d’une balle après son lancer.
Capture la distribution de probabilité que suivent les mots de la langue française du XVIIe.
Regroupe les items d’un site marchand qui sont achetés par les mêmes catégories de personnes.
Le modèle permet d’expliquer les données. Il n’a pas à être parfait (et il ne l’est jamais en pratique), mais on espère qu’il sera suffisamment bon pour mieux comprendre les relations qu’il caractérise ou simplement pour nous être utile pour la tâche souhaitée.
Apprentissage automatique¶
On sait que le but du ML est de produire un modèle qui capture les relations d’un dataset.
Pour y arriver, on dit que l’on entraîne un modèle sur un jeu de données, à l’aide d’un algorithme d'apprentissage automatique (Machine Learning algorithm).
Le domaine du ML regroupe beaucoup de modèles et d’algorithmes différents dans le but de couvrir un maximum de datasets possibles. Connaître les cas d’applications de chaque modèle et algorithme d’apprentissage est un bon moyen pour rapidement déployer des solutions à un problème donné.
Afin de bien apprendre, un modèle a besoin de beaucoup de données. C’est pourquoi il est courant de rencontrer des modèles entraînés à partir de millions d’images ou de documents. Plus un dataset contient d’exemples divers et plus il sera possible de modéliser des relations complexes entre nos données.
Tâches classiques résolues avec le ML¶
Nous pouvons maintenant nous intéresser aux différentes tâches classiques résolues à l’aide du ML. On va uniquement regarder les grandes familles de problèmes et donner quelques exemples pour chacune d’entre elles.
Classification¶
Le but d’une tâche de classification est de déterminer la classe des exemples d’un dataset (on parle de variable qualitative). Par exemple, on souhaite faire un modèle qui est capable de prédire si un mail est frauduleux ou pas. Dans ce cas, nous aurons besoin d’un ensemble de mails avec des informations sur le contenu du mail ainsi que sur son envoyeur et la classe du mail (« frauduleux » ou « non frauduleux »). Dans ce type d’exemples, on parle classification binaire car il y a uniquement deux classes.
Il existe de nombreux types de tâches de classification que vous pouvez rencontrer dans l’apprentissage automatique et des approches spécialisées de la modélisation qui peuvent être utilisées pour chacune. Ces approches seront étudiées plus en détail à la suite du cours.
Régression¶
Dans le domaine de l’apprentissage statistique, la régression cherche à prédire une quantité (on parle de variable quantitative). La régression s’articule autour d’algorithmes simples, qui sont souvent utilisés dans la finance, l’investissement et autres, et établit la relation entre une seule variable dépendante de plusieurs variables. Prédire le nombre de clics sur un lien ou prédire le rendement d’un plant de maïs sont des exemples de regression classiques. Le nombre à prédire peut être un nombre continu comme discret
Le modèle de régression le plus connu est la de régression linéaire.
Clustering¶
Le problème d’apprentissage non supervisé le plus fréquent est le problème de partitionnement de données (en anglais clustering). C’est l’étape où l’on essaie de séparer les données en groupes. Par rapport à la classification, ici il n’y a pas de classes bien définies. Les groupes sont construits sur le tas, à partir des similarités entre les données.
Le clustering permet d’identifier des groupes homogènes parmi une population donnée.
Association¶
La recherche des règles d’association est une méthode dont le but est de découvrir des relations ayant un intérêt entre deux ou plusieurs variables stockées dans de très importantes bases de données. Les algorithmes d’association sont particulièrement adaptés pour explorer des bases de données volumineuses ou complexes. Par exemple, ils peuvent identifier la probabilité de co-occurrence d’éléments dans une collection de données.
Quelques exemples:
Association entre alimentation et apparition de maladies.
Association entre génotype et phénotype.
Association entre activations de neurones et comportement.
Réduction de dimensions¶
Un second cas d’apprentissage non supervisé concerne la réduction de dimensions. Il désigne ainsi toute méthode permettant de projeter des données issues d’un espace de grande dimension dans un espace de plus petite dimension. Quand on parle de la dimension d’une donnée, on parle du nombre de features qui lui sont attachées. Dans cette situation on peut voir la réduction de dimension comme une étape de compression de l’information contenue dans nos données. Si cette compression est bien faite, on va garder uniquement les informations importantes et retirer le bruit.
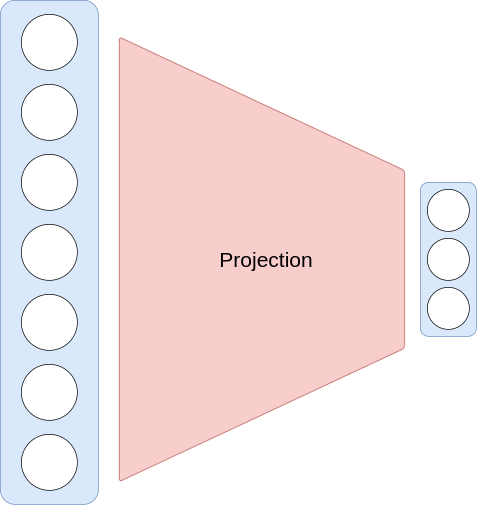
Fig. 1 Schéma d’une réduction de dimension.¶
On emploie ici le mot « dimension » au sens algébrique, i.e. la dimension de l’espace vectoriel sous-jacent aux valeurs des vecteurs de descripteurs. La réduction de dimensionnalité permet de réduire la complexité d’un problème d’apprentissage automatique à plusieurs niveaux :
D’un point de vue théorique, cela entraîne automatiquement une amélioration des propriétés de stabilité et de robustesse des algorithmes.
D’un point de vue pratique, cela simplifie la résolution du problème d’optimisation associé, en réduisant l’espace des solutions.
En d’autres termes, réduire la dimensionnalité limite le nombre de possibilités à tester, ce qui permet de traiter les données plus rapidement. Ce gain de temps est fonction de la dépendance de la complexité temporelle de l’algorithme par rapport à la dimension.
Différents types d’entraînements¶
L’approche ML pour résoudre un problème va dépendre de la tâche en question et des données disponibles. Ainsi, il est important de distinguer trois grandes familles d’algorithmes d’entraînement.
Apprentissage supervisé¶
Avec l’apprentissage supervisé, le modèle est entraîné à reproduire une sortie donnée. Par exemple, il peut apprendre à distinguer les photos de chien et de chat après qu’on lui ait montré des milliers de photos des deux catégories et en précisant pour chaque image à quelle catégorie elle appartient. Ou bien, il peut apprendre à traduire le français en chinois après avoir vu des centaines de milliers d’exemples de traduction français-chinois.
Concrètement, on a un dataset \(\mathcal{D} = (x_i, y_i)_1^N\) de \(N\) couples où \(x_i\) est un ensemble de caractéristiques (features) et \(y\) l’étiquette (label ou target) correspondante.
En reprenant l’exemple précédent, un \(x_i\) pourrait être les pixels d’une image de chien et \(y_i\) la catégorie chien.
On entraîne alors un modèle \(f\) tel que \(f(x) \approx y\).
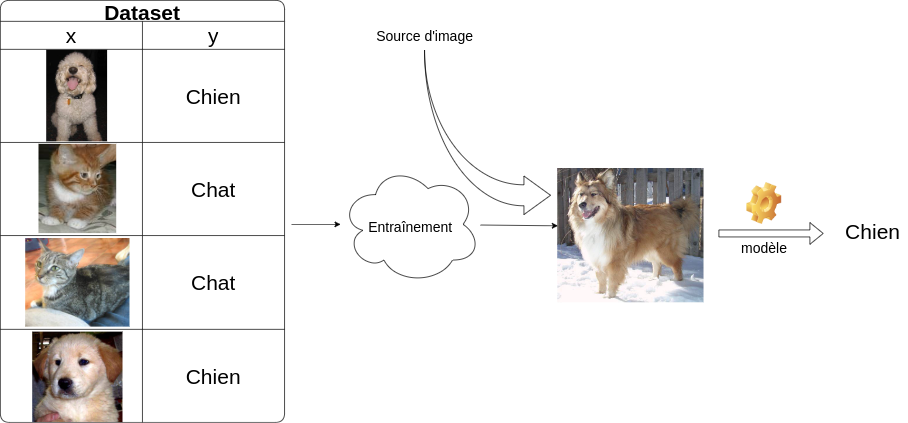
Fig. 2 Schéma d’une classification chien vs chat.¶
Dans le cadre de l’apprentissage supervisé, la machine connaît déjà les réponses qu’on attend d’elle. Elle travaille à partir de données étiquetées. Reprenons l’exemple d’une application destinée à reconnaître les chiens et les chats. Pour l’entraîner, on lui présente des images étiquetés comme « chien » ou « chat ». Par des techniques issues des statistiques et des probabilités, l’algorithme comprend alors quelles sont les caractéristiques qui permettent de classer ces images dans chacune des catégories. Ainsi, au fur et à mesure qu’on lui présentera de nouvelles images, il pourra les identifier, en donnant un score de probabilité.
Ce type d’apprentissage est particulièrement adapté pour résoudre les problèmes de classification et de régression.
Apprentissage non supervisé¶
Qu’est-ce que l’apprentissage non supervisé ? C’est de l’apprentissage sans superviseur, tout simplement… 😊 Plus sérieusement, l’apprentissage non supervisé consiste à apprendre à un modèle des informations sans l’aide d’étiquette, c’est-à-dire sans superviseur (d’où le nom, vous l’aurez compris).
Ce genre d’algorithme utilise uniquement un dataset \(\mathcal{D} = (x_i)_1^N\) contenant un ensemble de \(N\) données \(x\). En fonction de la tâche à résoudre, un tel apprentissage aura pour but de projeter les \(x_i\) dans un espace vectoriel de dimension plus faible ou bien à regrouper les \(x_i\) qui se ressemblent entre eux.
L’apprentissage non supervisé est particulièrement adapté pour résoudre les problèmes de clustering, d’association et de réduction de dimension.
Par renforcement¶
Le Reinforcement Learning ou l’apprentissage par renforcement (RL) est la science de la prise de décision. Il s’agit d’apprendre le comportement optimal dans un environnement donné pour obtenir une récompense maximale. Ce comportement optimal s’acquiert par des interactions avec l’environnement et l’observation de ses réactions.
Le problème du Reinforcement Learning implique qu’un agent explore un environnement inconnu pour atteindre un objectif. Le RL est basé sur l’hypothèse que tous les objectifs peuvent être décrits par la maximisation de la récompense cumulative attendue. L’agent doit apprendre à sentir et à perturber l’état de l’environnement en utilisant ses actions pour obtenir une récompense maximale. Un agent dans un état actuel S apprend de son environnement en interagissant avec ce dernier par le moyen d’actions. Suite à une action A, l’environnement retourne un nouvel état S’ et une récompense R associée, qui peut être positive ou négative.
Il est utile lorsque l’on sait récompenser un bon comportement mais qu’on ne saurait dire quelles sont les actions optimales d’un problème (difficile ou impossible d’avoir des étiquettes comme en supervisé). Par exemple aux échecs on sait quand un agent a bien joué (a-t-il perdu ou gagné la partie ?). Cependant, on ne sait pas donner quel est le coup optimal à n’importe quelle situation du jeu.
Le Reinforcement Learning a affiché des performances spectaculaires ces dernières années. Il a permis à des programmes d’apprendre par eux-mêmes dans des environnements complexe des stratégies extrêmement puissantes et robustes. Sous l’impulsion de DeepMind, ces algorithmes ont révolutionné l’intelligence artificielle dans de nombreux domaines, notamment dans le domaine des jeux, allant des jeux d’arcade (Agent57) et des jeux de plateau (AlphaGo) jusqu’aux jeux-vidéos (AlphaStar).
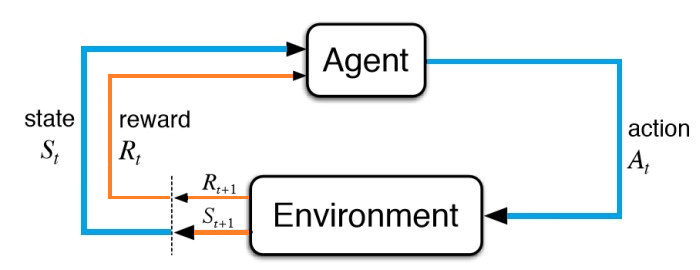
Fig. 3 Illustration entre l’agent RL et l’environnement.¶
Un cours est d’ailleurs entièrement dédié à ce vaste sujet.
Conclusion¶
Le but du ML est de capturer l’information contenue dans une base de données.
L’information est synthétisée à travers un modèle étant une fonction des features des données.
Diverses tâches sont résolues à l’aide du ML, les principales étant la classification, la régression et le clustering.
Un modèle est produit à l’aide d’algorithmes d’entraînement.
Divers algorithmes d’entraînements existes, ils sont regroupés dans trois catégories : l’apprentissage supervisé, l’apprentissage non supervisé et l’apprentissage par renforcement.