Feature Engineering
Contents
Feature Engineering¶
Introduction¶
Le feature engineering représente l’art de convertir les données de la meilleure façon possible, ce qui implique une combinaison d’expertise du domaine, d’intuitions et de procédés mathématiques. Ce cours a pour objectif d’être une référence concise pour les débutants avec la plupart des techniques simples mais largement utilisées pour cette approche. De prochains articles permettront d’approfondir chacuns des points abordés.
Le feature engineering est la partie la plus essentielle de la construction d’un projet de machine learning. Des centaines d’algorithmes à l’état de l’art apparaissent aujourd’hui à travers différentes thématiques, comme le Transfer Learning ou le Deep Learning. Au bout du compte, certains projets réussissent et d’autres échouent. Qu’est-ce qui fait la différence entre ces approches ? Le facteur le plus important est sans aucun doute la qualité des données et les features utilisées.
Méthodologie¶
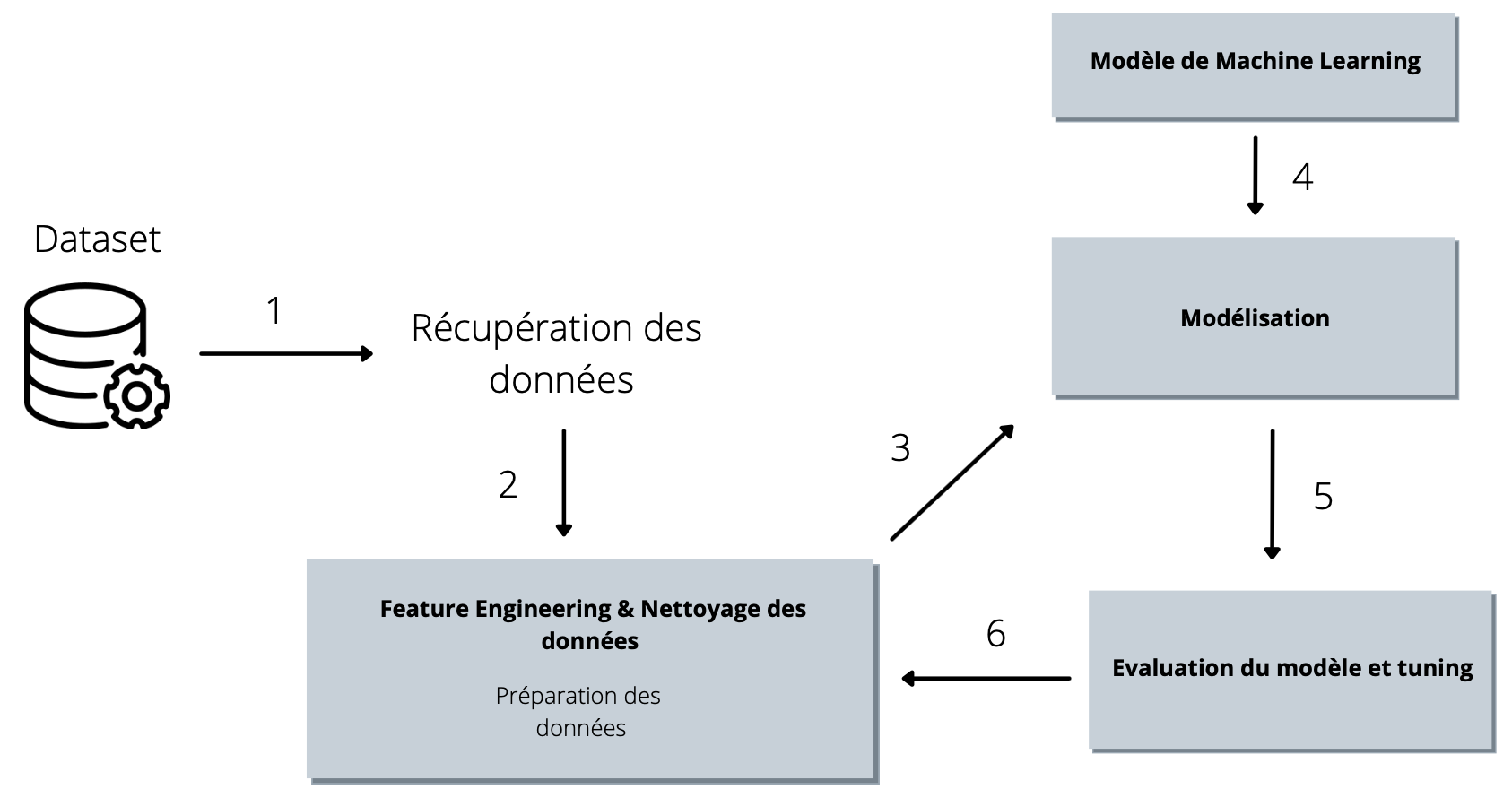
Fig. 8 Pipeline typique d’un projet de Machine Learning.¶
Supposons que vous êtes Data Scientist pour une entreprise. Votre manager vous demande d’atteindre une performance précise pour un modèle donné. Après avoir minutieusement exploré les données à votre disposition en ayant effectuer une EDA (Exploratory Data Analysis) digne de ce nom, vous décidez de vous lancer dans cette étape de préparation des données puis d’utiliser votre modèle favori. Néanmoins vous constatez que les performances de votre modèle sont bien plus basses que prévues et vous craignez de perdre votre poste !
En tant que Data Scientist agueri, vous décidez de collaborer avec le Data Engineer de votre équipe pour vous concentrer, le temps d’une après-midi, sur cette étape de feature engineering. Ensemble vous décidez de vous attarder sur la qualité des données pour ne pas injecter des features qui auront un impact négatif sur les performances de votre modèle.
Le Data Engineer vous dit de ne pas paniquer. Pour résoudre ce problème, il vous conseille de réitèrer l’étape n°6 en sa compagnie tant que les objectifs de performances du modèle donné par votre N+1 ne sont pas atteints.
A retenir :
La qualité des données et des features ont le plus d’impact sur un projet de Machine Learning et fixent la limite de ce que vous pouvez faire. La qualité de vos prédictions et le bien fondé de votre approche repose essentiellement sur ces aspects.
Nettoyage des données¶
La première étape lorsqu’on évoque le concept de “feature engineering” consiste au nettoyage des données. Celle-ci repose sur différents aspects importants que nous aborderons dans cette partie.
Valeurs manquantes¶
Définition : Aucune valeur n’est enregistrée dans une certaine observation pour une variable donnée.
Pourquoi les données manquantes sont-elles importantes ?
Certains algorithmes ne peuvent pas fonctionner en présence de valeurs manquantes même pour les algorithmes qui traitent les données manquantes, sans traitement, le modèle peut conduire à des prédictions inexactes.
Une étude sur l’impact des données manquantes sur différents algorithmes Machine Learning peut être trouvée ici.
Valeurs aberrantes¶
Définition : Une observation aberrante est une observation qui s’écarte tellement des autres observations que l’on peut soupçonner qu’elle a été générée par un mécanisme différent.
Les observations aberrantes, selon le contexte, méritent une attention particulière ou doivent être complètement ignorées. Par exemple, une transaction inhabituelle sur une carte de crédit est généralement le signe d’une activité frauduleuse, tandis qu’une taille de 1600 cm d’une personne est très probablement due à une erreur de mesure et doit être filtrée ou imputée par autre chose.
Pourquoi la valeur aberrante est-elle importante ?
La présence de valeurs aberrantes peut :
Empêcher l’algorithme de fonctionner correctement
Introduire des bruits dans l’ensemble de données
Rendre les échantillons moins représentatifs
Certains algorithmes sont très sensibles aux valeurs aberrantes. Par exemple, Adaboost peut traiter les valeurs aberrantes comme des cas “difficiles” et leur accorder un poids considérable, ce qui produit un modèle à mauvaise généralisation. Tous les algorithmes qui reposent sur les moyennes/variances sont sensibles aux valeurs aberrantes, car ces statistiques sont fortement influencées par les valeurs extrêmes.
D’autre part, certains algorithmes sont plus robustes aux valeurs aberrantes. Par exemple, les arbres de décision ont tendance à ignorer la présence de valeurs aberrantes lorsqu’ils créent les branches de leurs arbres. En général, les arbres effectuent des séparations en demandant si la variable x >= la valeur c, et donc la valeur aberrante tombera de chaque côté de la branche, mais elle sera traitée de la même manière que les autres valeurs, quelle que soit son ampleur.
Valeurs rares¶
Définition : Variable dont certaines valeurs n’apparaissent que rarement.
Dans certaines situations, les valeurs rares, comme les valeurs aberrantes, peuvent contenir des informations précieuses sur l’ensemble de données et nécessitent donc une attention particulière. Par exemple, une valeur rare dans une transaction peut indiquer une fraude.
Pourquoi les valeurs rares sont-elles importantes ?
Les valeurs rares ont tendance à provoquer un overfitting. Un grand nombre de labels peu fréquents ajoute du bruit, avec peu d’informations, ce qui entraîne un ajustement excessif aux données. Les labels rares peuvent être présents dans l’ensemble d’apprentissage, mais pas dans l’ensemble de test, ce qui entraîne un ajustement excessif de l’ensemble d’apprentissage.
Les labels rares peuvent apparaître dans l’ensemble de test, mais pas dans l’ensemble d’entraînement. Ainsi, le modèle ne saura pas comment l’évaluer.
Haute cardinalité¶
Définition : Le nombre de labels au sein d’une variable appelé cardinalité. Un nombre élevé de labels au sein d’une variable est connu comme une cardinalité élevée.
Pourquoi une cardinalité élevée est-elle importante ?
Les variables comportant trop de labels ont tendance à dominer celles qui n’en comportent que quelques-unes, en particulier dans les algorithmes basés sur des arbres. Un grand nombre de labels dans une variable peut introduire du bruit avec peu ou pas d’informations, ce qui rend les modèles d’apprentissage automatique susceptibles d’être overfittés.
Certains labels peuvent n’être présents que dans l’ensemble de données d’apprentissage, mais pas dans l’ensemble de test, ce qui entraîne une suradaptation des algorithmes à l’ensemble d’apprentissage.
À l’inverse, de nouveaux labels peuvent apparaître dans l’ensemble de test alors qu’ils n’étaient pas présents dans l’ensemble d’apprentissage, ce qui empêche l’algorithme d’effectuer un calcul sur la nouvelle observation.
Feature Scaling¶
Définition : Le feature scaling est une méthode utilisée pour normaliser des variables indépendantes ou des features. Dans le traitement des données, elle est également connue sous le nom de normalisation des données et est effectuée durant l’étape de prétraitement des données.
Pourquoi le Feature Scaling est-il important ?
Si la taille des entrées varie, avec certains algorithmes vous pouvez obtenir des résultats incohérents.
La descente de gradient converge beaucoup plus rapidement lorsque la normalisation à l’échelle des features est effectuée. La descente de gradient est un algorithme d’optimisation communément utilisé dans la régression logistique, les SVM, les réseaux neuronaux, etc. qui a été introduite précédemment.
Comment gérer le Feature Scaling ?
La normalisation (mise à l’échelle du score Z) supprime la moyenne et met les données à l’échelle de la variance unitaire : \(Z=\frac{X - X_{mean}}{std}\) où std correspond à l’écart type. La feature est remise à l’échelle pour avoir une distribution normale standard centrée autour de 0 avec un écart type de 1. Si la variable est asymétrique ou comporte des valeurs aberrantes, cela comprime les observations dans une plage étroite, ce qui nuit au pouvoir prédictif.
Scaling Min-Max transforme les features en mettant à l’échelle chaque feature dans une plage donnée. La valeur par défaut est entre \([0,1]\). \(X_{scaled}=\frac{X - X_{min}}{X_{max}-X_{min}}\) compresse les observations dans la plage étroite si la variable est asymétrique ou comporte des valeurs aberrantes.
Comme nous pouvons le voir, la normalisation et la méthode Min-Max comprimeront la plupart des données dans une plage de valeurs restreintes.
On remarquera que la suppression des valeurs aberrantes est un autre sujet du nettoyage des données qui doit être effectuée au préalable de cette étape.
Feature Encoding¶
Pourquoi le Feature encoding est-il important ?
On appelle ‘variables catégorielles’ les données qui prennent généralement un nombre limité de valeurs possibles. En outre, les données de la catégorie ne doivent pas nécessairement être numériques, elles peuvent être de nature textuelle. Tous les modèles de Machine Learning sont une sorte de modèle mathématique qui a besoin de chiffres pour fonctionner. C’est l’une des principales raisons pour lesquelles nous devons prétraiter ces données dites ‘catégorielles’ avant de les transmettre aux modèles.
Cette étape de transformation des strings / des variables catégorielles en nombres est une étape primordiale pour que les algorithmes puissent traiter ces valeurs. Même si vous voyez qu’un algorithme peut prendre en charge des entrées catégorielles, il est très probable que l’algorithme intègre ce processus de feature encoding.
One-hot Encoding : Remplace la variable catégorielle par différentes variables booléennes (0/1) pour indiquer si un certain label est vrai ou faux pour une observation donnée.
Cette méthode permet de conserver toutes les informations de cette variable.
Néanmoins, elle présente deux défauts :
elle élargir considérablement l’espace des features si trop de labels sont présents au sein de cette variable.
n’ajoute pas de valeur supplémentaire pour rendre la variable plus prédictive.
Count-Frequency Encoding : Remplace chaque label de la variable catégorielle par le nombre/fréquence dans cette catégorie
Cette méthode présente un défaut :
permet d’attribuer le même encodage pour deux labels différentes (si elles apparaissent en même temps, avec le même nombre d’occurences) et perd des informations précieuses.
Feature Selection¶
Définition : Processus de sélection d’un sous-ensemble de features pertinents à utiliser dans la mise en place de modèles de Machine Learning.
“Plus il y a de données, meilleur sera le résultat de mon modèle”, vous avez sans doute entendu cette phrase plusieurs fois, mais elle n’est pas toujours vraie. L’inclusion de features non pertinentes (celles qui ne sont pas utiles à la prédiction) et de features redondantes (non pertinentes en présence d’autres features) ne fera que surcharger le processus d’apprentissage et entraînera facilement un overfitting.
Avec la feature selection, nous pouvons :
une simplification des modèles pour les rendre plus faciles à interpréter
des temps d’apprentissage plus courts et des coûts de calcul moindres
réduire le coût de la collecte des données
éviter la malédiction de la dimensionnalité
une meilleure généralisation en réduisant l’overfitting
Nous devons garder à l’esprit que différents sous-ensembles de features offrent des performances optimales pour différents algorithmes.
Une méthode populaire de sélection des features consiste à mélanger de manière aléatoire les valeurs d’une variable spécifique et de déterminer comment cette permutation affecte la métrique de performance de l’algorithme. En d’autres termes, l’idée est de permuter les valeurs de chaque features, une à la fois, et de mesurer dans quelle mesure la permutation diminue la précision, la ROC_AUC, ou la MSE du modèle d’apprentissage automatique. Si les variables sont importantes, c’est-à-dire hautement prédictives, une permutation aléatoire de leurs valeurs diminuera considérablement n’importe laquelle de ces métriques. En revanche, les variables non importantes / non prédictives ne devraient avoir que peu ou pas d’effet sur la mesure de performance du modèle que nous évaluons.
Sources & Application¶
Pour appliquer au sein de vos projets les différentes notions qui ont été abordées dans cet article, voici une sélection de ressources préalablement sélectionnées :